8. 性能优化
模型部署时,用户在跑通结果后,会有进一步的性能优化需求,此节将从完整的模型性能优化流程来介绍如何调优。并展开介绍用户最常用的操作:模型性能分析,图级别优化,算子级别优化。完整优化流程如下图所示:
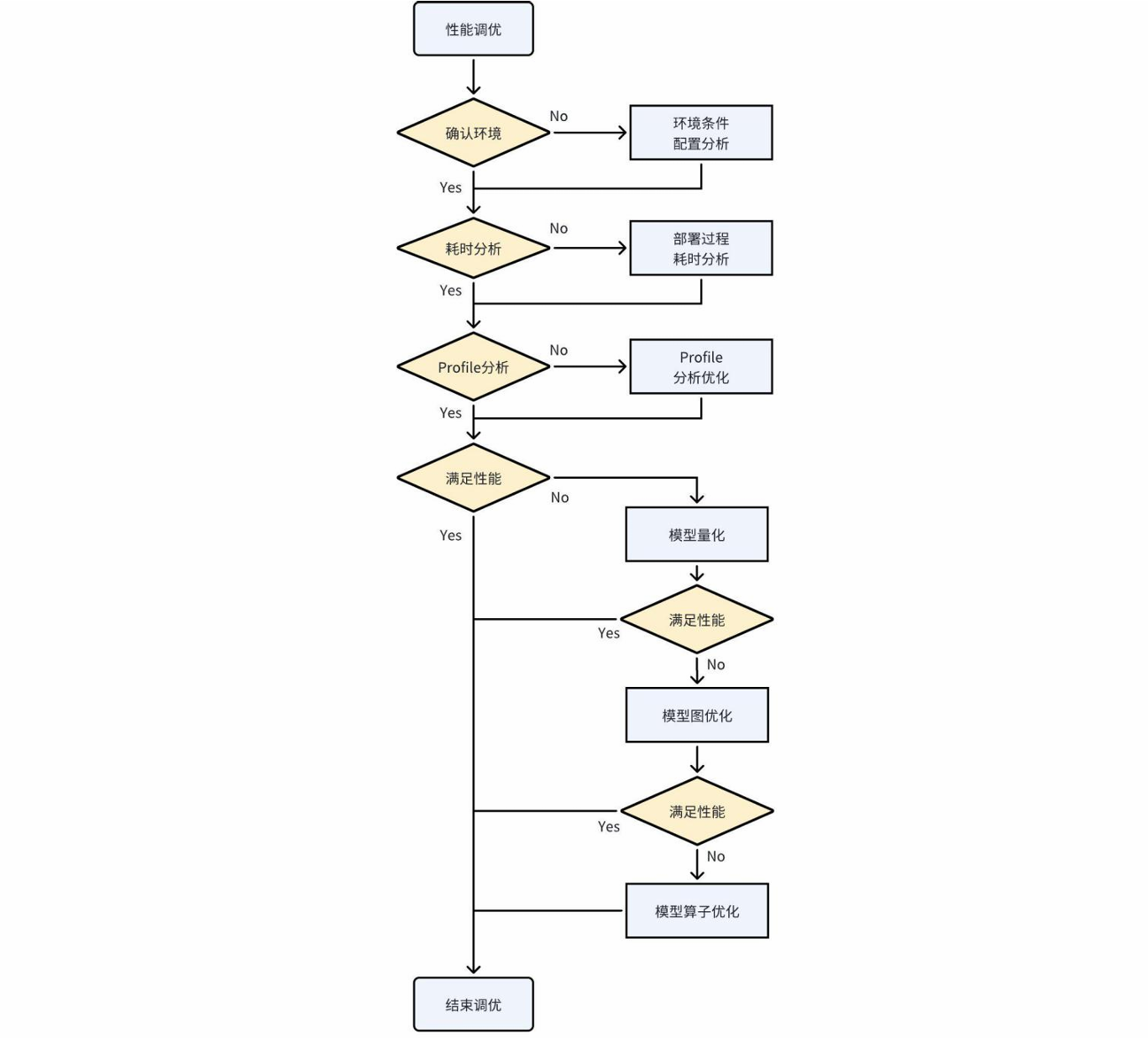
8.1 模型性能优化前期分析流程
8.1.1 环境条件与配置检查
在所有性能分析及优化之初,应该优先确定测试环境的基准,只有在基准相同时,所测性能数据才是有意义的。例如非定频下测试同一模型的推理性能波动幅度是比较大的,无法以某一批测试耗时作为平均的单帧耗时。
查询和设置测试环境的条件和配置有如下几个方面:
查询和设置CPU、DDR、NPU频率
定频频率直接影响运行速率,频率越高性能相对越好。频率变化与性能提升不是线性关系。频率增加相对来说功耗也会增加。定频命令参考如下:https://github.com/airockchip/rknn_model_zoo/blob/main/scaling_frequency.sh
也可以简单的使用如下命令设置为性能模式:
echo performance | tee $(find /sys -name '*governor') /dev/null || true
检查NPU内核Driver版本
有些功能或者算子的性能优化项与内核驱动版本有关,较新的内核驱动版本能应用到最新的底层优化实现。所以请检查是否使用到较新的内核驱动版本,目前建议更新到0.9.2之后的版本。该环节非强制更新。
检查内核驱动版本命令如下:
cat /sys/kernel/debug/rknpu/version # for RK3566/RK3568/RK3588/RK3562/RK3576
cat /proc/rknpu/version # for RV1106系列/RV1103系列
检查NPU的负载
NPU的负载为单位时间内NPU执行任务的时间占比。负载能够反应NPU的繁忙程度,如果查询到的负载较低,则表明NPU等待任务提交的时间较长,需要检查数据输入输出拷贝用时、应用程序前后处理优化等等。或者在应用程序中使用多线程处理方式来提升NPU负载。
另外需要注意的是,NPU的负载不代表实际的MAC利用率,MAC利用率反应的是执行中任务在NPU硬件单元中的执行效率。
查询NPU负载的命令如下:
cat /sys/kernel/debug/rknpu/load
# or
cat /proc/debug/rknpu/load
8.1.2 部署过程耗时分析
整个部署程序的推理部分耗时的占用有如下三个方面:用户应用程序耗时、输入输出数据拷贝耗时、模型推理耗时。分析各环节耗时占比能够直观的确定优化重点。测定这些步骤的耗时可以在应用程序上通过打时间戳的方式获得。
用户应用程序耗时
用户应用程序耗时主要指推理过程中非NPU相关的耗时,一般来说主要是数据的前处理、后处理和逻辑代码的耗时。这部分耗时由用户全权控制。用户在发现应用程序的耗时占总体耗时非常高时,除精简优化代码以外,可以尝试将一部分操作通过专用硬件加速。
例如将一些矩阵乘加操作,采用Matmul API接口来调用NPU辅助执行计算。又如部分图像的缩放类操作可以调用RGA的接口来实现加速。
输入输出拷贝耗时
当采用通用API时,用户设置的输入输出内存与NPU的内存是存在拷贝耗时的,这个耗时可以在调用通用API时打印出来。拷贝耗时取决于DDR与CPU的性能,在输入输出数据量较小的时候Normal API的拷贝耗时较低,但数据量较大时,Normal API的耗时就不可忽略。因此更多推荐采用零拷贝API。
当采用零拷贝API时,用户设置的输入输出内存被NPU直接访问,所以输入输出拷贝耗时为0。零拷贝的接口的使用详细参考RKNN Runtime零拷贝调用章节。
推理耗时
NPU执行推理的耗时,该部分耗时直接体现部署模型的耗时。受推理模型规模、编译优化版本影响。RKNN的LOG打印的推理耗时在不同
RKNN_LOG_LEVEL等级时不一样,因为LOG打印存在一定的耗时。一般在查看单帧推理耗时,设置的LOG等级为1,并且跑多次取平均为准。
8.2 模型性能分析
8.2.1 获取Profile信息
当需要了解模型推理逐层耗时情况时,可以在运行程序前输入以下指令打印详细信息:
export RKNN_LOG_LEVEL=4
./run_rknn_test ./test.rknn ./input.jpg
如果是Android平台,运行后可以通过logcat命令获取详细日志。
如果是使用rknn-toolkit2,你可以使用如下方式来获取每层的耗时:
rknn.init_runtime(target='platform', perf_debug=True)
rknn.eval_perf()
性能分析报告信息如下(仅截出性能相关部分)
 图8-2 性能分析报告
图8-2 性能分析报告
图8-3 性能分析报告
可以针对总体性能Profile和逐层性能Profile快速定位想要的信息。并根据数据来制定后续不同侧重的优化策略。获得Profile后可以进行如下分析:分析逐层耗时,找出高耗时算子;分析非NPU算子影响;分析NPU算子性能瓶颈。下文将详细讨论。
8.2.2 分析逐层耗时
如下图中,可以从Time一栏找出耗时高的算子,优先优化高耗时算子。也可以兼顾观察Op Type一栏找出高耗时的算子是不是属于同类OpType,以便统一优化。
 图8-4 高耗时算子性能分析
值得说明的是,高耗时算子不一定是低效算子,某些算子是高算力消耗的,高耗时的算子如果MAC利用率很高时,应该考虑能否降低此算子的尺寸规模以减少耗时。但当利用率很低的高耗时算子出现时,这类算子就是优化重点。
图8-4 高耗时算子性能分析
值得说明的是,高耗时算子不一定是低效算子,某些算子是高算力消耗的,高耗时的算子如果MAC利用率很高时,应该考虑能否降低此算子的尺寸规模以减少耗时。但当利用率很低的高耗时算子出现时,这类算子就是优化重点。
8.2.3 分析CPU算子影响
如下图中,可以看到某些高耗时的算子是运行在CPU上的,将这些CPU算子NPU化将可以极大改善高耗时影响。一般来说,用户的大部分性能优化问题都会在将CPU算子NPU化后得到解决。因此要重点注意CPU算子的耗时情况。
 图8-5 CPU算子性能分析
图8-5 CPU算子性能分析
一般来说算子运行在非NPU上的原因有如下几种:
算子尺寸超限(查询OpList文档的算子尺寸限制)
算子尚未支持在NPU上运算(查询OpList是否支持该算子,可以在Github工程上提Issue)
NPU硬件限制无法支持(是否可以算法等效成其他NPU可支持的其他实现)
8.2.4 分析NPU算子性能瓶颈
考虑NPU算子的高耗时问题时,可以根据DDR Cycles/NPU Cycles/Total Cycles这三栏来判断该算子耗时的理论瓶颈是带宽瓶颈还是算力瓶颈。这里的DDR Cycles是根据NPU频率换算过后的数据,指该层算子读写数据换算成NPU频率下所需的Cycle数,因此可以直接与NPU Cycle比较。
如下图所示:
 图8-6 NPU算子性能瓶颈分析
图8-6 NPU算子性能瓶颈分析
其中第三层
DDR Cycles远大于NPU Cycles时,说明该层读写数据花费Cycle数量远大于运算所需Cycle数量,所以该Conv瓶颈来自带宽。其中第十二层
DDR Cycles远小于NPU Cycles时,说明该层读写数据花费Cycle数量远小于运算所需Cycle数量,所以该Conv瓶颈来自算力。
目前NPU Cycles一栏主要显示Conv所需的Cycles,其他算子类型后续会逐步补充。
8.3 量化加速
模型量化能大幅降低模型的运算规模,节约带宽消耗。由于采用了INT8的量化的卷积采用的是INT8的运算单元计算。同时算力上,相比于Float16的运算单元,INT8的运算单元规模更大,理论算力更高。模型量化的具体使用方式详见量化说明。
8.4 图级别优化
模型的图级别优化是最容易从整体角度去统筹优化模型的方法。在分析出耗时占比较高的算子或图区域后,我们可以有多种不同的方式去改造图进而达成优化的目的。图优化主要以节省多余算子、非NPU OP的NPU化、面向硬件高效率算子改造等为目标。这些目标有可能有些时候是存在矛盾的,例如为了非NPU OP的NPU化,可能需要额外多出几个算子,看似违背了节省多余算子的目标,但总体推理性能提升,便是有意义的。
在RKNN-Toolkit2工具链中,软件栈在转换模型的过程中已经会进行一定程度上的图优化。但这一过程不是万能和尽善尽美的,有些未被考虑的场景仍然会出现冗余的操作,用户可以根据本节介绍的一些思路来进行预先性的图优化。以下仅作为每一种优化方法的介绍,不是强制固定,实际场景需要灵活运用。
8.4.1 非NPU OP通过图变换实现NPU化
对于非NPU op,可以做一些等效的图变换来,替换成NPU可支持的算子,以达成NPU化的优化目的。
例如下图,以shufflenetv2_0.5模型为例,将其中channel shuffle操作改为卷积近似替换。weight数值为0/1,可以达成重排数据的效果,假如无法在NPU实现该Transpose、Reshape操作,可以将这些算子整合成Conv算子实现数据重排。
 图8-7 卷积重排
图8-7 卷积重排
8.4.2 利用硬件Fuse特性设计网络或图优化
NPU支持一些算子组合进行融合,可以适当调整部分算子的运算流程,以适应NPU的融合规则实现算子融合优化。
尽管RKNN软件栈会有一定程度的图优化,但无法做到全面覆盖到所有情况。某些特殊情况下出现了理论上可融合简化,但最终图优化未能融合的图结构,用户可以算法上手动调整以快速解决该优化问题。
例如下图,在不改变计算正确性的情况下,通过调整Transpose与Clip算子的顺序,使得Conv与Clip融合运算,提高了性能。
 图8-8 算子图优化/融合
图8-8 算子图优化/融合
利用融合规则设计,融合规则如下:
| 已支持的融合规则 | 未来计划支持的融合规则 |
|---|---|
Conv+Relu |
Activation+Add(Mul) |
Conv+PRelu(LeakyRelu) |
Add(Mul)+Activation |
Conv+Clip |
Conv+Mul |
Conv+Sigmoid(Tanh/Elu/Silu...) |
Conv+Activation+Mul |
Conv+Add |
Conv+Activation+Pooling |
Conv+Activation+Add |
Conv+Activation+Add(Mul)+Pooling |
8.4.3 算法等效变换或者子图单OP化
在分析某个图区域时,有时算法上要实现某个行为功能可能设计上追求表达的直白性不会考究具体部署上的性能影响,容易产生出复杂冗余的图结构,可以通过算法等效的方式,将某个区域的子图单OP化,减少算子计算步骤,达成优化目的。
例如下图为Yolov5-nano等效图变换,将若干复杂的Slice取数融合到Conv中,形成一个新的Conv,极大简化了图结构。
方案来源:https://github.com/ultralytics/yolov5/issues/4825
 图8-9 算子等效图变换
图8-9 算子等效图变换
8.4.4 算子等效进行“同类项合并”、“提取公因式”
某些算子连续多次运算时,可以简省合并为同一个算子,如Reshape、Transpose、Slice、部分Add/Mul/Sub/Div等。
例如下图可以通过简单调整图顺序以达成同类算子合并目的。
 图8-10 同类项算子合并
图8-10 同类项算子合并
某些图结构有一些共有部分的同类型操作可以调整顺序以提取成单一操作。
例如下图可以通过调整算子顺序将重复性的同类算子单独提取出来只执行一次操作。
 图8-11 重复性算子合并
图8-11 重复性算子合并
8.5 算子级别优化
模型的算子级别优化是针对性比较强的细节优化,对于某些特定算子的具体改造设计,以期进一步提升性能。算子的优化更多是针对性进行算子尺寸设计,以硬件实现效率最高的尺寸规格运行,例如某些算子尺寸规模相似,对齐与非对齐的运行耗时可能差别巨大,差别的原因在于硬件对于部分非对齐尺寸的算子会需要额外的冗余操作来保证正确性,因此算子的尺寸设计对于模型性能也能起到很大的影响,用户可以根据如下一些思路来进行预先性的算子优化。
8.5.1 面向DDR性能优化的OP尺寸设计(非强制)
在一些对齐尺寸下,除NPU运算效率更高外,对于DDR的读写也更友好,同等带宽条件下,更友好的读写会提升DDR的带宽效率,从而达到更好的性能。以下列出一些对于DDR读写更友好的尺寸规则,这些规则不强制。
Channel按对齐量对齐
对齐表格如下所示:
表8-1 RK3566/RK3568
| Conv | Depthwise Conv | Other OP | ||
|---|---|---|---|---|
| Dtype | InputChannel | OutputChannel | Input & Output Channel | Input & Output Channel |
| Int8 | 32 | 16 | 32 | 8 |
| Int16 | 16 | 8 | 16 | 4 |
| Float16 | 16 | 8 | 16 | 4 |
| BFloat16 | 16 | 8 | 16 | 4 |
表8-2 RK3588/RK3576
Conv |
Depthwise Conv |
Other OP |
||
|---|---|---|---|---|
Dtype |
InputChannel |
OutputChannel |
Input & Output Channel |
Input & Output Channel |
Int8 |
32 |
32 |
64 |
16 |
Int16 |
32 |
16 |
32 |
8 |
Float16 |
32 |
16 |
32 |
8 |
BFloat16 |
32 |
16 |
32 |
8 |
TFloat32 |
16 |
16 |
16 |
4 |
表8-3 RV1106/RV1103
Conv |
Depthwise Conv |
Other OP |
||
|---|---|---|---|---|
Dtype |
InputChannel |
OutputChannel |
Input & Output Channel |
Input & Output Channel |
Int8 |
32 |
16 |
32 |
16 |
Int16 |
16 |
16 |
16 |
8 |
表8-4 RK3562
Conv |
Depthwise Conv |
Other OP |
||
|---|---|---|---|---|
Dtype |
InputChannel |
OutputChannel |
Input & Output Channel |
Input & Output Channel |
Int8 |
32 |
16 |
32 |
16 |
Int16 |
32 |
8 |
16 |
8 |
Float16 |
32 |
8 |
16 |
8 |
BFloat16 |
32 |
8 |
16 |
8 |
TFloat32 |
16 |
8 |
8 |
4 |
Height * Width > 1时4对齐同等规模的算子,
Width大Height小的尺寸,面向DDR读写更友好。如下图所示,右图卷积效率高于左图卷积
 图8-12 同等规格卷积对比
图8-12 同等规格卷积对比
8.5.2 高利用率模型算子的设计
要在模型设计上整体提高算力的利用率,一般要尽量避免低效算子,以及选择容易跑出更高利用的算子尺寸设计。这里主要列出一些可以尽可能避免的低效算子、讨论卷积尺寸与利用率的关系。
规避低效算子原则设计
模型中尽量减少低效算子的使用,低效算子主要有三类,如表8-5所示
表8-5 三类低效算子
| 数据搬运类 | 尺寸变换类 | 非Relu类激活函数 |
|---|---|---|
Transpose |
Resize |
Sigmoid |
Reshape |
Tile |
Tanh |
Split |
Pooling |
Softplus |
Concat |
Pad |
Hardswish |
卷积尺寸与利用率关系的讨论
由于卷积的性能会受到算力和带宽的双重影响,在评估性能时常采用MAC利用率来说明硬件算力发挥程度。
卷积尺寸与硬件算力和带宽读写相关,因此这里讨论卷积尺寸与利用率关系,作为用户设计模型的性能参考辅助。以下根据经验数据来作为一个大致的参考:
以下名词注释:KH(kernel height),KW(kernel width),KC(kernel channel),type_bytes(权重位宽除以8),Ksize(KW或KH),Kstride(KW或KH方向上的stride)
卷积的输入输出
Tensor的Channel符合对齐要求时(见8.4.1中对齐表格数据),利用率更高。输入
Tensor的Channel < 256时利用率相对较高,当Channel > 512以后,随着Channel增大,利用率会逐渐下降。权重尺寸上,
KH*KW*KC*type_bytes < 6K Bytes时利用率相对较高。当超过一定大小后利用率会明显下降。Ksize / Kstride的比值越大,利用率相对更高。例如(Ksize=3, Kstride=1优于Ksize=2, Kstride=1)输出
Tensor的Height * Width < 16时利用率下降。输出
Tensor的Channel越大,利用率越高。
以上讨论仅是考察独立尺寸影响利用率的因素,实际部署模型里的卷积所呈现出的实测利用率则是诸多因素综合后的结果,开发者如果对某一卷积性能不够满意,希望通过提升利用率以优化其性能,可以参考上述尺寸与利用率关系的讨论进行针对性调整。
8.5.3 子图融合的匹配
RKNN软件栈会将某些特定的图关系匹配成自定义算子,如下图所示,如果没有被融合成对应的算子,可以考察一下是否连接关系不同没有匹配上。
 图8-13 Glu子图融合
图8-13 Glu子图融合
 图8-14 LayerNorm子图融合
图8-14 LayerNorm子图融合
目前已经支持的子图融合规则有:
Split + Sigmoid + Mul -> GLU
ReduceMean + Sub + Pow + ReduceMean + Add + Sqrt + Div (+ Mul + Add) -> LayerNorm