9. 内存使用优化
9.1 模型运行时内存组成及分析方法介绍
9.1.1 RKNN模型运行时内存组成
RKNN模型运行时内存主要由权重和internal tensor、寄存器配置、输入输出tensor四种组成。运行时的内存通常是在rknn_init的时候创建完成。
9.1.2 模型内存分析方法
在rknn_init()接口调用完毕后,当用户需要查看模型分配的内存或者需要外部分配模型权重的时候,调用rknn_query接口,传入RKNN_QUERY_MEM_SIZE即可查询模型的权重、internal的内存(不包括输入和输出)、模型推理所用的所有 DMA 内存以及 SRAM 内存(如果SRAM没开或者没有此项功能则为0)的占用情况。
以下是示例代码:
rknn_context ctx = 0;
// Load RKNN Model
int ret = rknn_init(&ctx, model_path, 0, NULL, NULL);
if(ret < 0) {
printf("rknn_init fail! ret=%d\n", ret);
return -1;
}
// Get weight and internal mem size
rknn_mem_size mem_size;
ret = rknn_query(ctx, RKNN_QUERY_MEM_SIZE, &mem_size, sizeof(mem_size));
if(ret != RKNN_SUCC) {
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
printf("total weight size: %d, total internal size: %d\n", mem_size.total_weight_size, mem_size.total_internal_size);
9.2 如何使用外部分配内存
9.2.1 输入输出内存外部分配
根据章节C API零拷贝整体流程里提到的,如果用户使用零拷贝API,可以在外部分配内存给输入输出tensor,然后配置给NPU使用,具体流程可以参照C API零拷贝整体流程里的流程图。注意,要用外部内存分配的方式,只能使用零拷贝API。该方法主要适用场景是用户需要手动分配内存给NPU使用,而不是通过rknn_create_mem()接口来让NPU自己分配内存。
外部内存可以用物理地址和fd记录,主要通过下面2个接口创建:
rknn_create_mem_from_phys():通过物理地址来创建rknn_tensor_mem的结构体rknn_create_mem_from_fd():通过fd来创建rknn_tensor_mem的结构体
这里提供了一个用mpi_mmap创建内存的例子。该例子通过rknn_create_mem_from_phys()接口,引入外部内存的物理地址,创建一个rknn tensor mem的结构体带物理内存的信息。以下是示例代码:
// Create input tensor memory
rknn_tensor_mem* input_mems[1];
// default input type is int8 (normalize and quantize need compute in outside)
// if set uint8, will fuse normalize and quantize to npu
input_attrs[0].type = input_type;
// default fmt is NHWC, npu only support NHWC in zero copy mode
input_attrs[0].fmt = input_layout;
input_mems[0] = rknn_create_mem_from_phys(ctx, input_phys, input_virt, input_attrs[0].size_with_stride);
...
// Create output tensor memory
rknn_tensor_mem* output_mems[io_num.n_output];
for (uint32_t i = 0; i < io_num.n_output; ++i) {
output_mems[i] = rknn_create_mem_from_phys(ctx, output_physs[i], output_virts[i], output_attrs[i].size);
}
// Set input tensor memory
ret = rknn_set_io_mem(ctx, input_mems[0], &input_attrs[0]);
if (ret < 0) {
printf("rknn_set_io_mem fail! ret=%d\n", ret);
return -1;
}
// Set output tensor memory
for (uint32_t i = 0; i < io_num.n_output; ++i) {
// set output memory and attribute
ret = rknn_set_io_mem(ctx, output_mems[i], &output_attrs[i]);
if (ret < 0) {
printf("rknn_set_io_mem fail! ret=%d\n", ret);
return -1;
}
}
除了引用外部内存的物理地址外,还可以通过引用fd的方式来使用外部分配内存,示例代码如下:
int mb_flags = RK_MMZ_ALLOC_TYPE_CMA | RK_MMZ_ALLOC_UNCACHEABLE;
// Allocate weight memory in outside
MB_BLK weight_mb;
rknn_tensor_mem* weight_mem;
ret = RK_MPI_MMZ_Alloc(&weight_mb, mem_size.total_weight_size, mb_flags);
if (ret < 0) {
printf("RK_MPI_MMZ_Alloc failed, ret: %d\n", ret);
return ret;
}
void* weight_virt = RK_MPI_MMZ_Handle2VirAddr(weight_mb);
if (weight_virt == NULL) {
printf("RK_MPI_MMZ_Handle2VirAddr failed\n");
return -1;
}
int weight_fd = RK_MPI_MMZ_Handle2Fd(weight_mb);
if (weight_fd < 0) {
printf("RK_MPI_MMZ_Handle2Fd failed\n");
return -1;
}
weight_mem = rknn_create_mem_from_fd(ctx, weight_fd, weight_virt, mem_size.total_weight_size, 0);
printf("weight mb info: virt=%p, fd=%d, size: %d\n", weight_virt, weight_fd, mem_size.total_weight_size);
int mb_flags = RK_MMZ_ALLOC_TYPE_CMA | RK_MMZ_ALLOC_UNCACHEABLE;
// Allocate weight memory in outside
MB_BLK weight_mb;
rknn_tensor_mem* weight_mem;
ret = RK_MPI_MMZ_Alloc(&weight_mb, mem_size.total_weight_size, mb_flags);
if (ret < 0) {
printf("RK_MPI_MMZ_Alloc failed, ret: %d\n", ret);
return ret;
}
void* weight_virt = RK_MPI_MMZ_Handle2VirAddr(weight_mb);
if (weight_virt == NULL) {
printf("RK_MPI_MMZ_Handle2VirAddr failed\n");
return -1;
}
int weight_fd = RK_MPI_MMZ_Handle2Fd(weight_mb);
if (weight_fd < 0) {
printf("RK_MPI_MMZ_Handle2Fd failed\n");
return -1;
}
weight_mem = rknn_create_mem_from_fd(ctx, weight_fd, weight_virt, mem_size.total_weight_size, 0);
printf("weight mb info: virt=%p, fd=%d, size: %d\n", weight_virt, weight_fd, mem_size.total_weight_size);
9.2.2 模型内存的外部分配
在9.1的章节提到模型内存占用有两部分,一部分是internal内存,另外一部分是weight内存。应用如果需要使用外部分配的模型内存,可以通过接口rknn_set_weight_mem(),rknn_set_internal_mem()接口设置模型weight和internal使用的内存。参考示例如下:
// Load RKNN Model
ret = rknn_init(&ctx, model_virt, model_size, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
TIME_END(rknn_init);
if (ret < 0) {
printf("rknn_init fail! ret=%d\n", ret);
return -1;
}
// query and inset input / output tensor
...
// Allocate weight memory in outside
MB_BLK weight_mb;
rknn_tensor_mem* weight_mem;
ret = RK_MPI_MMZ_Alloc(&weight_mb, SIZE_ALIGN_128(mem_size.total_weight_size), mb_flags);
void* weight_virt = RK_MPI_MMZ_Handle2VirAddr(weight_mb);
int weight_fd = RK_MPI_MMZ_Handle2Fd(weight_mb);
weight_mem = rknn_create_mem_from_fd(ctx, weight_fd, weight_virt, mem_size.total_weight_size, 0);
ret = rknn_set_weight_mem(ctx, weight_mem);
if (ret < 0) {
printf("rknn_set_weight_mem fail! ret=%d\n", ret);
return -1;
}
printf("weight mb info: virt=%p, fd=%d, size: %d\n", weight_virt, weight_fd, mem_size.total_weight_size);
// Allocate internal memory in outside
MB_BLK internal_mb;
rknn_tensor_mem* internal_mem;
ret = RK_MPI_MMZ_Alloc(&internal_mb, SIZE_ALIGN_128(mem_size.total_internal_size), mb_flags);
void* internal_virt = RK_MPI_MMZ_Handle2VirAddr(internal_mb);
int internal_fd = RK_MPI_MMZ_Handle2Fd(internal_mb);
internal_mem = rknn_create_mem_from_fd(ctx, internal_fd, internal_virt, mem_size.total_internal_size, 0);
ret = rknn_set_internal_mem(ctx, internal_mem);
if (ret < 0) {
printf("rknn_set_internal_mem fail! ret=%d\n", ret);
return -1;
}
printf("internal mb info: virt=%p, fd=%d, size: %d\n", internal_virt, internal_fd, mem_size.total_internal_size);
9.3 Internal内存复用
RKNN API提供了外部管理NPU内存的机制,通过RKNN_FLAG_MEM_ALLOC_OUTSIDE参数,用户可以指定模型中间的feature内存由外部分配。该功能的典型应用场景如下:
部署时,所有NPU内存均是用户自行分配,便于对整个系统内存进行统筹安排。
用于多个模型串行运行场景,中间
feature内存在不同上下文复用,特别是针对RV1103/RV1106这种内存极为紧张的情况。
例如,下图中有两个模型,模型1的Internal Tensor占用大于模型2,如果模型1和模型2顺序地运行,可以只开辟0x00000000~0x0000c4000地址的一块内存给模型1和2共用,模型1推理结束后,这块内存可以被模型2用来读写Internal Tensor数据,从而节省内存。
 图9-1 两个模型Internal Tensor共享同一块内存地址空间的示例图
假设模型1的路径是model_path_a,模型2路径是model_path_b,示例代码如下:
rknn_init(&ctx_a, model_path_a, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_a, RKNN_QUERY_MEM_SIZE, &mem_size_a, sizeof(mem_size_a));
rknn_init(&ctx_b, model_path_b, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_b, RKNN_QUERY_MEM_SIZE, &mem_size_b, sizeof(mem_size_b));
// 获取两个模型最大的internal size
max_internal_size = MAX(mem_size_a.total_internal_size, mem_size_b.total_internal_size);
internal_mem_max = rknn_create_mem(ctx_a, max_internal_size);
// 设置a模型internal memory
internal_mem_a = rknn_create_mem_from_fd(ctx_a, internal_mem_max->fd,
internal_mem_max->virt_addr, mem_size_a.total_internal_size, 0);
rknn_set_internal_mem(ctx_a, internal_mem_a);
// 设置b模型internal memory
internal_mem_b = rknn_create_mem_from_fd(ctx_b, internal_mem_max->fd,
internal_mem_max->virt_addr, mem_size_b.total_internal_size, 0);
rknn_set_internal_mem(ctx_b, internal_mem_b);
9.4 多线程复用上下文
在多线程场景中,一个模型可能会被多个线程同时执行,如果每个线程都单独初始化一个上下文,那么内存消耗会很大,因此可以考虑共享一个上下文,避免数据结构重复构造,减少运行时内存占用。RKNN API提供了复用上下文的接口,接口定义如下:
int rknn_dup_context(rknn_context* context_in,rknn_context* context_out)
其中,context_in是已初始化的上下文,而context_out是复用context_in的上下文。如下图所示,两个context的模型结构相同,因此可以复用上下文。
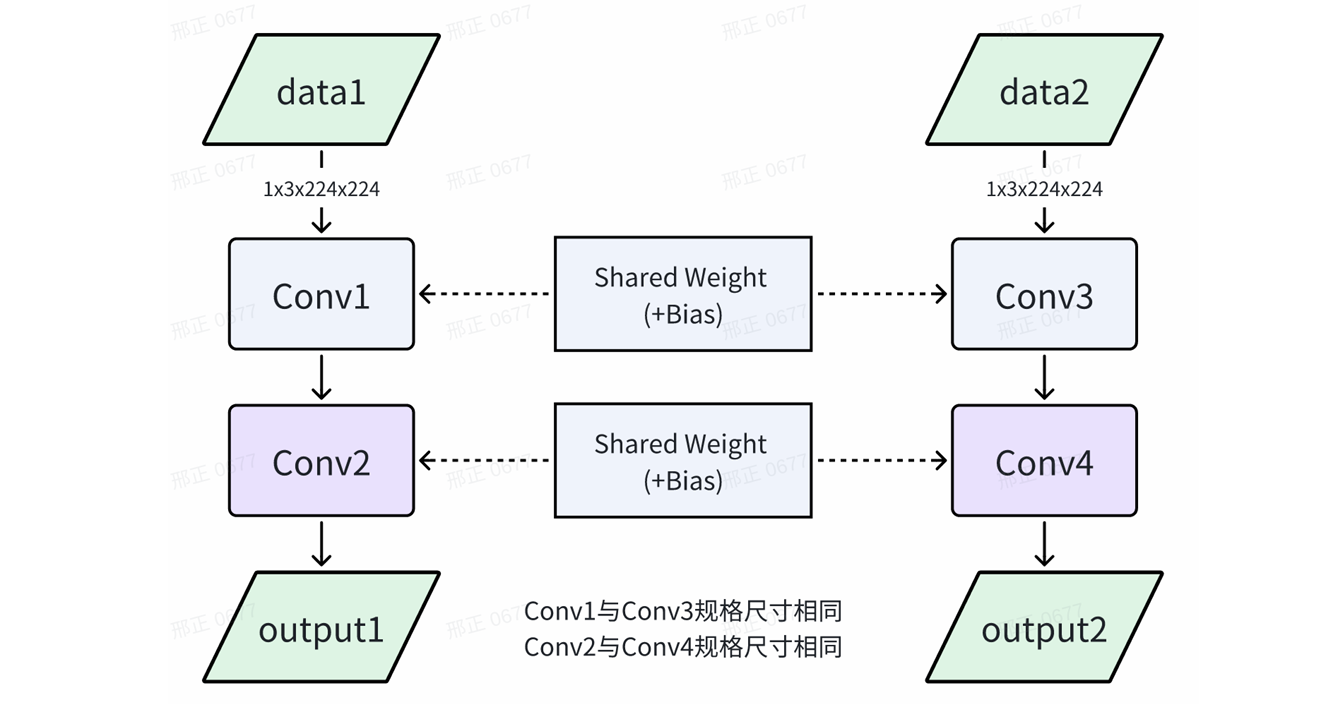
9.5 多种分辨率模型共享相同权重
当多个不同分辨率模型有相同的权重时,可以共享相同的权重,以减少内存占用。在RKNPU SDK<=1.5.0版本时,此功能可以以较小的内存占用实现不同分辨率模型间的动态切换。在1.5.0版本后,该功能被动态shape功能替代。
如下图所示,模型A和模型B的权重完全相同。
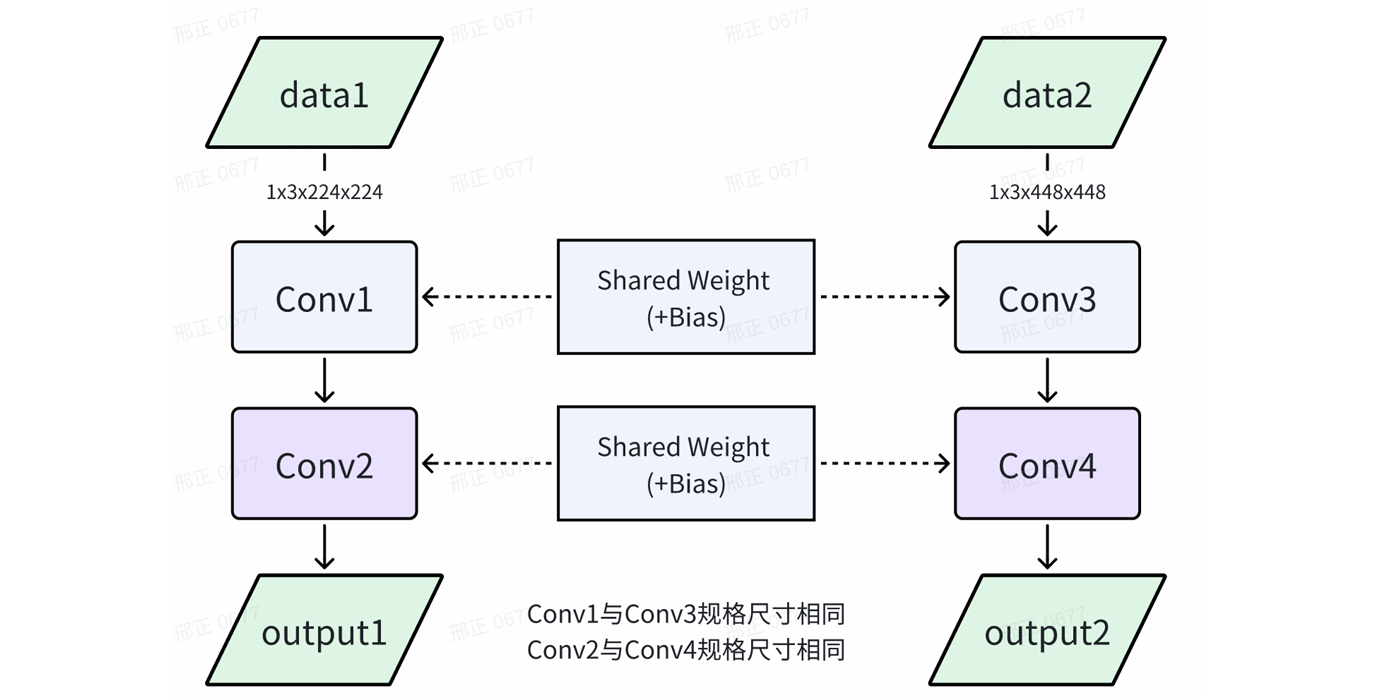
可按照以下步骤实现多分辨率模型共享相同权重:
在转换RKNN模型时,其中一个模型设置为主模型,rknn.config接口设置参数remove_weight=False,另一个模型设置为从模型,设置参数remove_weight=True。主RKNN模型包含权重,从RKNN模型不包含卷积类权重。
部署时,先初始化主RKNN模型,再初始化从RKNN模型。初始化从模型时,使用RKNN_FLAG_SHARE_WEIGHT_MEM标志,并新增rknn_init_extend参数,该参数值为主模型的上下文。假设主模型路径是model_A,从模型路径是model_B,示例代码如下:
rknn_context context_A;
rknn_context context_B;
ret = rknn_init(&context_A,model_A,0,0,NULL);
...
rknn_init_extend extend;
extend.ctx = context_A;
ret = rknn_init(&context_B, model_B,0,RKNN_FLAG_SHARE_WEIGHT_MEM,&extend)